

---懒骨黄毛 20200802
写文0经验,一开始打算是写一些性能优化方面的尝试,如何降低数据库压力,避免锁死,拉高TPS的同时,从业务逻辑层面保证优化后还遵循着原子性,巴拉巴拉。但是,好巧不巧,周五晚上聊天时聊上了架构升级,想学点新的弄西(可能只对我来说是新的555),也当做是对自己学习的笔记了。
Flink的图标是一只松鼠,象征着灵活快速的特点。
附个网址:https://ci.apache.org/projects/flink/flink-docs-release-1.8/
Apache Flink is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
要讲讲Flink得讲讲现在大多通用的数据结构。

传统数据结构
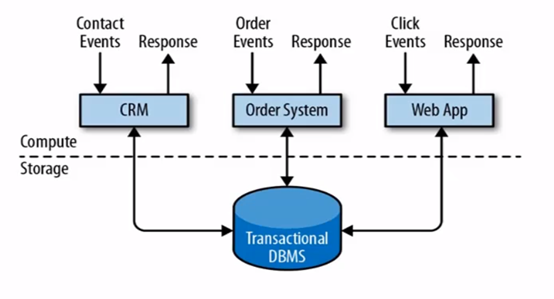
这种传统数据结构就是典型事务处理应用场景使用的,基本流程就是访问-逻辑处理-库操作-返回,总分可以分为计算层和储存层,具有最终数据一致性保障。但这种小规模场景应用还可以应付,高并发或大数据的场景下,就算多个Tomacat可以分流分压,通过消息队列去抗,数据库接口的压力还是会压垮整个系统(差点跑题跑到优化去了)。总之这种传统的结构在单体结构在小场景下效率很高,但随着后面业务繁重,系统庞大,在臃肿的数据库中进行修改会付出很大代价,且不适合应用高并发,大数据场景。
分析处理场景
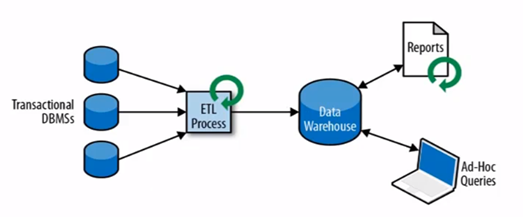
这种应用场景不太熟,应该算是最基本的大数据处理结构。一般是从多个数据库中抽取数据到数仓中,再进行分析处理,生成相关报告和统计信息,这种结构有能力处理大数据,但有高延迟。
流式处理
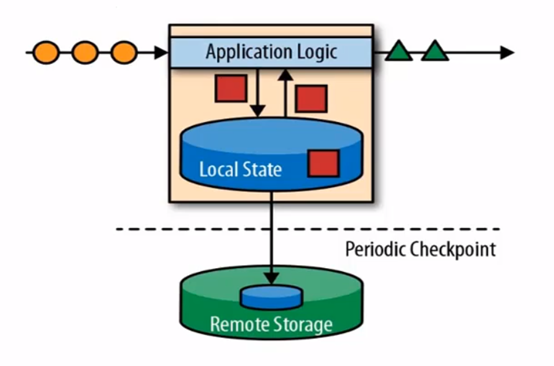
能不能像工厂流水线一样处理原始数据呢,流式处理就是这样一个思想,这种结构能满足高性能、高吞吐、低延时等特性吗。所谓状态,就是处理原始数据锁生成的中间计算结果,当新数据流入时会基于中间状态结果的基础上进行运算。那为了高吞吐,就会做成分布式,做成分布式就会有乱序问题,因为流水是不能打乱的,为了保证顺序,得通过定时状态监测,监测通过才会进行外部状态储存。就算如此,结果可能还是会有错误。
Lambda架构
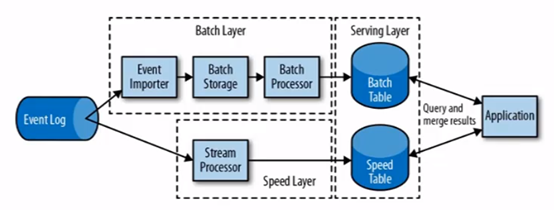
不多赘述,这套结构采用两套系统来保证数据的准确性,就是融合怪。基于两套API去设计一个东西,相当于平时用流处理来快速计算出结果,即使结果可能有误差。隔三差五又拿全量数据去批量处理,复杂度和运维人员的掉发量拉满。
然后Flink就是他们几个的私生子
右边就是Flink的结构,既可以快速响应,也可以作为中间计算结果继续进行流计算。
不过这种特性,一般都是用再去了解的,就不在多赘述了,直接放在最后边。
批处理和流处理其实差不多,无非就是把一段段批量数据当做原子来操作。
目前初学Flink,就暂时介绍下Deemo
整一个maven项目
Pom.xml贴些依赖和打包工具,主要用scala编程,引用Flink组件,较新的版本会要求更高的Maven和JDK。
[code lang="xml" show_lang=true]<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将 Scala 代码编译成 class 文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<!-- 声明绑定到 maven 的 compile 阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>[/code]

敲一下好了,然后去resources文件夹建个TXT,随便写点歪比巴卜
给个HelloWorld
[code lang="scala"]import org.apache.flink.api.scala._
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
/*
* HelloWorld
* 需要创建一个执行环境
* 然后读取txt数据
* 然后对数据进行切分,再按单词分组聚合
* */
object WordCount {
def main(args: Array[String]): Unit = {
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val inputFilePath: String = "E:\\Flink\\tutorial\\src\\main\\resources\\test.txt"
val inputDataSet: DataSet[String] = environment.readTextFile(inputFilePath)
//下面操作分别为自行设定规则切割,存词计数,分组,求和
val resultDataSet: DataSet[(String,Int)] = inputDataSet
.flatMap(_.split(" "))
.map((_,1))
.groupBy(0)
.sum(1)
resultDataSet.print()
}
}[/code]
下周再写跟Flink的组件
1.1 Flink 的重要特点
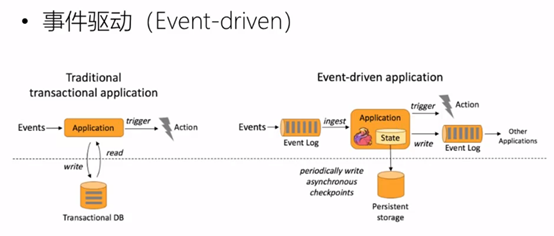
- 事件驱动型(Event-driven)
事件驱动型应用是一类具有状态的应用, 它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 kafka 为代表的消息队列几乎都是事件驱动型应用。
与之不同的就是 SparkStreaming 微批次,如图:
事件驱动型:
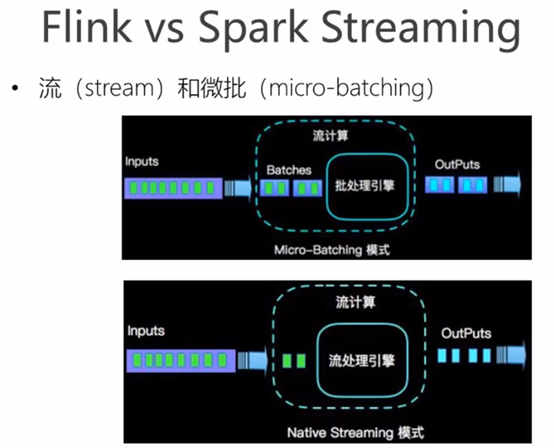
- 流与批的世界观
批处理的特点是有界、持久、大量, 非常适合需要访问全套记录才能完成的计算工作, 一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在 spark 的世界观中,一切都是由批次组成的, 离线数据是一个大批次, 而实时数据是由一个一个无限的小批次组成的。
而在 flink 的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
无界数据流: 无界数据流有一个开始但是没有结束,它们不会在生成时终止并
提供数据,必须连续处理无界流,也就是说必须在获取后立即处理 event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取 event,以便能够推断结果完整性。
有界数据流: 有界数据流有明确定义的开始和结束,可以在执行任何计算之前
通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
1.1.3 分层 api
最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function) 被嵌入到 DataStream API 中。底层过程函数( Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心 API( Core APIs) 进行编程,比如 DataStream API( 有界或无界流数据) 以及 DataSet API(有界数据集)。这些 API 为数据处理提供了通用的构建模块, 比如由用户定义的多种形式的
转换( transformations),连接( joins),聚合( aggregations),窗口操作( windows) 等等。DataSet API 为有界数据集提供了额外的支持, 例如循环与迭代。这些 API 处理的数据类型以类( classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API 遵循( 扩展的)关系模型:表有二维数据结构( schema)( 类似于关系数据库中的表),同时 API 提供可比较的操作,例如 select、project、join、group-by、aggregate 等。Table API 程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何。
尽管 Table API 可以通过多种类型的用户自定义函数( UDF)进行扩展,其仍不如核心 API 更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外, Table API 程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与
DataStream 以及 DataSet 混合使用。
Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与Table API 类似,但是是以 SQL 查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
目前 Flink 作为批处理还不是主流,不如 Spark 成熟,所以 DataSet 使用的并不是很多。Flink Table API 和 Flink SQL 也并不完善,大多都由各大厂商自己定制。所以我们主要学习 DataStream API 的使用。实际上 Flink 作为最接近 Google DataFlow 模型的实现,是流批统一的观点,所以基本上使用 DataStream 就可以了。
Flink 几大模块
- Flink Table & SQL(还没开发完)
- Flink Gelly(图计算)
- Flink CEP(复杂事件处理)
Comments 2 条评论
图已经对不上文章了,不过看着懒得改了
:parrots.quad:这排版绝力,建议重造